

Faculty of Electrical Engineering, Mathematics and Computer Science
Department of Telecommunications
Network Architectures and Services Group
Application-Layer Multicast:
Comparative Analysis of M-CAN and Scribe
N. I. Cempaka Wangi
Supervisor : Prof. dr. ir. P. van Mieghem
Mentor : Ir M. Janic
Date : 9 July 2004
M.Sc. Thesis No : PVM 2004-029
Abstract
The slow deployment of network-layer IP Multicast has triggered some researchers to propose Application-Layer multicast schemes, a promising alternative that is expected to enhance the network layer multicast development on a long run. In the last two years, a great number of algorithms have been proposed. However, most of the proposed solutions are not scalable, and therefore not suitable for many target applications. Implemented over structured peer-to-peer overlay networks, CAN-based multicast (M-CAN) and Scribe are two algorithms that claim to support application layer multicast in a highly scalable manner.
All Application-Layer multicast proposals claim to achieve a higher performance quality than the unicast, while lower than that of the native IP. In this thesis we evaluated the performance of two scalable Application-Layer multicast algorithms, M-CAN and Scribe, in terms of the number of hops. We implemented both algorithms under two extreme conditions, no topology awareness and absolute topology awareness, and compared them mutually, as well as to m-Unicast and IP Multicast. In addition, to reduce the number of duplicate messages, we introduced some improvements to M-CAN algorithm. Finally we compared the number of duplicated packet on the overlay network caused by both original and improved M-CAN algorithms.
Our simulation have shown that using absolute topology awareness information, Scribe achieves the best performance quality, i.e. has the lowest hop count, after IP Multicast among other schemes. However, without topology awareness, Scribe’s performance decreases extremely, until for some condition it is worse than those of others. Without topology awareness to create the overlay, the original M-CAN algorithm has the lowest performance, even compared to m-Unicast. Finally, our simulation showed that the improved M-CAN algorithm almost eliminates duplicate message routings in the application level and therefore, reduces its total hop count. Even without topology awareness, its hop count is lower than those of the original algorithm and m-Unicast.
Acknowledgement
I would like to acknowledge Prof. Ir. P. Van Mieghem to provide facilities for conducting this thesis, Ir. M. Janic for her supervisions, suggestions and comments. I also would like to acknowledge Ir. F. Kuipers, Ir. R. Hekmat and Ir. A. Slingerlands for helping me solving some problems during this work.
I would also thank to special people in my live, my husband, Ir. M.Reza who encourages me to study at TU Delft and especially when I finished this work, my mother who always supports me in my whole live, especially to take care of my son, M.Rifqi in the last two months of this work, and my father who supports me financially to study in the Netherlands. Finally, to all my family and friends that I cannot mention them one by one.
Contents
Abstract 1
Acknowledgement 2
1. Introduction 5
1.1 Background Problems 5
1.2 The Thesis Goal 5
1.3 The Thesis Structure 5
2. Network vs. Application Layer Multicast 6
2.1 Network Layer Multicast 6
2.2 Application Layer Multicast 7
2.2.1 Tree-based approach 7
2.2.2 Mesh-based approach 8
2.2.3 Overlay-based approach 8
2.3 Network vs. Application Layer Multicast Performance 9
3. CAN-based Multicast (M-CAN) 11
3.1 Content Addressable Network 11
3.1.1 CAN Construction 12
3.1.2 Routing in a CAN 12
3.1.3 Neighboring in CAN 12
3.1.4 Topology Awareness CAN overlay network 13
3.2 CAN-based Multicast (M-CAN) 13
3.2.1 The Group Formation 13
3.2.2 The Forwarding Algorithm 14
3.2.2.1 The Static Multicast Forwarding 14
3.2.2.2 The Dynamic Multicast Forwarding 16
4. SCRIBE 19
4.1 PASTRY 19
4.1.1 Pastry Design 19
4.1.2 Routing in Pastry 19
4.1.3 Routing Performance 22
4.1.4 Locality Property 22
4.2 SCRIBE 22
4.2.1 Group Management 22
4.2.2 Membership Management 22
4.2.3 Joining the Multicast Group 23
4.2.4 Multicast Message Distribution 23
5. Simulation Design 24
5.1 General Scenario 24
5.2 Multicast Schemes Simulation 25
5.2.1 IP Multicast 25
5.2.2 M-CAN 26
5.2.3 Scribe 29
5.2.4 m-Unicast 31
6. Simulation Results and Analysis 33
6.1 CAN-based multicast 33
6.1.1 Probability density function 33
6.1.2. Comparison of M-CAN1 and M-CAN2 performance 39
6.1.3 Effect of M-CAN overlay creation 45
6.2 SCRIBE 53
6.2.1 Probability density function 53
6.2.2 Comparison of Scribe1 and Scribe2 performance 56
6.2.3 Effects of varying NPastry 59
6.3. Comparison of M-CAN, Scribe, IP Multicast and m-Unicast mechanisms 63
6.3.1. Comparison with three different types of M-CAN overlay simulation 63
6.3.2. Comparison with Scribe simulation under variation of NPastry 69
7. Conclusions and Future Works 76
7.1 Conclusions 76
7.2 Future Works Possibility 77
References 78
Appendix A1: C-Codes for M-CAN Simulation
Appendix A2: C-Codes for SCRIBE Simulation
Appendix A3: C-Codes for IP Multicast and m-Unicast Simulation
Appendix B: Simulation Results
1
Introduction
1.1 Background Problems
IP multicast mechanism is an efficient way to provide point to multipoint communication. It r, emoves unnecessary packet duplication in the network and therefore conserves a significant amount of bandwidth. However, due to complexity and scaling problems, after being developed for more than a decade, this protocol has not been widely employed over Internet network. Application layer multicast is a promising alternative that is expected to speed up the network layer multicast deployment on a long run. Unlike the native scheme, the multicast functionality is now performed in the application layer. The multicast group is formed logically on the application level. Instead of routers, end hosts individually handle the packet duplication and routing. Consequently, application-layer multicast cannot perform as well as the native one, because redundant traffics on physical links are unavoidable. In the last two years, a great number of algorithms have been proposed [1,3-6,8,10,15]. However, most of proposed solutions are not scalable, and therefore not suitable for some target applications. Recently, some researchers have proposed scalable application layer multicasts e.g. NICE, Bayeux, CAN-based multicast, Scribe etc. that are implemented over structured peer-to-peer overlay networks.
1.2 The Thesis Goal
The main goal of this thesis is to evaluate the performance of two scalable application layer multicast algorithms, M-CAN and Scribe. We compare them mutually, as well as to unicast and IP Multicast. The performance metric we used for comparison is the number of hops. Furthermore, we introduce our improvements to CAN-based algorithm to improve its performance in terms of the number of duplicate packets. To the best of our knowledge, no such comparison has been done so far.
1.3 The Thesis Structure
This thesis is organized as follows: In Chapter I the background problem, goal and layout of this thesis are presented. Chapter II gives the general description of Application Layer Multicast, why it emerged and its broad classification. Chapter III reviews the CAN overlay network and CAN-based multicast, how the multicast groups are managed and how multicasting is performed. Here, we also introduce our improvements to the proposed algorithm. Chapter IV explains Pastry overlay network and Scribe. In Chapter V we describe simulation designs of five compared schemes: CAN-based Multicast with and without improvements, Scribe, Unicast and IP multicast. Chapter VI presents the simulation results and analysis. Finally, in chapter VII conclusions and future work possibilities are given.
2
Network vs. Application Layer Multicast
2.1 Network Layer Multicast
Internet Protocol (IP) Multicast is an efficient way to deliver packets to a large-scale group of communication application [13]. It reduces the traffic load in the network by simultaneously delivering a single stream of data to thousands of recipients. It also delivers the information without adding any additional load on the source or the receivers using the least network bandwidth of any competing technology. The source only sends a packet once and it will reach every destination without unnecessary duplicate packets. In the unicast system, if a source wants to send a packet to many destinations, it has to send same packets as many times as the number of destinations, which increases the traffic load on the network. Therefore, the multicast system is suitable for multipoint applications, such as videoconferencing, corporate communications, distance learning, and distribution of software, news, etc.

Figure 2.1 Unicast mechanism

Figure 2.2 Multicast mechanism
IP multicasting relies on two mechanisms: a group management protocol to establish and maintain multicast groups, and multicast routing protocols to route packets efficiently. On the traditional Internet architecture, both mechanisms are applied on the network layer level. Routers are responsible to duplicate packets and route them to each destination without redundancy. However, some serious problems appear on the multicast implementations. Here, we will name some of them. First, routers have to maintain per group state, which causes larger routing tables, higher complexity and serious scaling constrains in IP layer. Second, IP Multicast is a best effort service and providing some features such as robustness, congestion control and security are more difficult than in a unicast system. Third, no good business model has been made yet to get the revenue expectation of this system. Finally, to perform multicast functions, routers need to be modified, causing changes in the infrastructure network. Those problems make the IP multicast not very attractive for the operators and further limit developments of multicast applications.
2.2 Application Layer Multicast
An alternative to solve IP multicast problems is to move the multicast functionality from network layer to application layer, at which end hosts hold responsibilities to form a multicast group to replicate and forward packets among group members. The group is formed in a logical manner at the application layer beyond the underlying Internet network where every host decides how many packets it should replicate and to whom it will forward them. Moreover, higher layer features can be supported using a well-understood unicast solution. Unlike network-layer multicast, application layer multicast requires no infrastructure support and can be easily deployed in the Internet. Thus, the developments no longer depend on routers, but can be performed individually by end-hosts.
During the last two years, numbers of application layer multicast algorithms have been proposed [1,3-6,8,10,15]. Most of them converge in three broad categories: mesh, tree and overlay-based approaches.
2.2.1 Tree-based approach
In this approach, group members directly self-organize into a shared tree by explicitly picking a parent for each new member. Yoid [5], ALMI [8], BTP, Overcast [6] and HMTP [15] adopt this approach although each of them uses different tree building algorithms. Yoid and HMTP construct single shared trees for all sources. Both of them define a distributed tree building protocol between the end hosts. ALMI uses a centralized algorithm to create a minimum-spanning tree rooted at a designated single source of multicast data distribution. Members of a multicast group measure the distance between themselves using network metrics. Based on those measurements a controller creates a minimum spanning tree to disseminate the multicast message. The Overcast protocol applies a single source broadcast and constructs trees rooted at that source. A set of proxies is organized into a distribution tree rooted at a central source for single source multicast and a distributed tree building protocol is used to create this source specific tree, in a manner similar to Yoid.
2.2.2 Mesh-based approach
This approach performs multicast mechanism in two steps. First, an overlay mesh is created to connect members of a multicast group. Based on this mesh, a per-source tree for multicast delivery is built by using a well-known routing algorithm. Examples of algorithm using this approach are End System Multicast and Scattercast [4]. The most important part here is determining which link to keep, which to delete, and how to do both efficiently. The advantages of this approach are (1) an existing routing algorithm can be used to construct the tree and (2) loop avoidance.
The appearance of a mesh-based approach is motivated by the demand of multi-source application, such as videoconference. Single shared trees as adapted by tree-based approach, are not optimized for the individual source and susceptible to a central point of failure.
However, both mesh and tree approaches face scalability problem. To build the delivery tree, most of them run a conventional routing algorithm such as Distance Vector Multicast Routing Protocol (DVMRP). Usually, end hosts do not have available routing information; instead they must rely on end-to-end measurements between themselves. In such algorithm, every node has to announce its estimated distance of every possible destination to its local neighbors, so that every node maintains information for all other nodes in the topology. Yet, every node has to learn about topology changes, e.g. a node joins or leaves a multicast group, updates its routing table and announces it to its neighbors so that each node knows about it. Those needs for member discovery and memberships maintenance finally limit these algorithms to support only small group sizes.
2.2.3 Overlay-based approach
Regarding the scalability problem, a number of application layer multicast systems built using overlay networks have been proposed [3,10,16].
An overlay network is a virtual network built in the application level where each node in the network has an abstract namespace. This network may be created by considering or NOT considering the underlying Internet network, depending on a technique used to build it. A number of structured peer-to-peer (p2p) overlay networks e.g. CAN [9], Chord [12], Pastry [11] and Tapestry [16] have emerged nowadays, providing an efficient routing over namespaces to support a large scale of application communication.
A structured peer-to-peer overlay network can be used to provide Internet-scale application-level multicast. Bayeux [17], CAN-based multicast [10] and Scribe [3] are some of the proposed protocols that are argued to have abilities to support large group sizes in a fashionable way. Each uses a different type of overlay network to implement Internet-scale application level multicast either by flooding (CAN-based multicast) or tree building (Bayeux, Scribe). Further, this thesis only examined CAN-based multicast and Scribe as representatives of scalable overlay-based application-level multicast schemes.
The CAN-based multicast (M-CAN) uses a Content-Addressable Network (CAN) as an overlay network to disseminate the multicast message. A CAN is a network whose elements virtually form a d-dimensional Cartesian coordinate. Every node in the CAN has its own separated zone, which assemble the total space of CAN. The M-CAN uses an extended CAN overlay structure and applies a flooding mechanism to perform multicast services. For each group, a separate overlay network is built and the routing information of the group’s overlay is used to broadcast messages. This scheme offers two key advantages:
· Scalable. By exploiting the flooding mechanism on CAN topologies, the need for multicast routing algorithms to construct distribution trees can be eliminated. Hence, it is appropriate for a very large (thousands of nodes) group sizes without restricting the service model to a single source.
· Low complexity. A CAN is naturally a structured network that is built easily. Therefore, a CAN based multicast comes at lower complexity and added protocol mechanism.
Scribe is a tree-building application level multicast infrastructure built on top of Pastry. A Pastry is an overlay network that uses a circular 128-bit namespaces. Each node within the overlay has a unique randomly chosen nodeId. Pastry is a distributed and scalable p2p system to support a variety of applications such as file sharing, file storage, group communication and naming systems. Scribe uses Pastry to build a per-group multicast tree to multicast the message along the group. This scheme offers two key advantages:
· Scalable. Both Pastry and Scribe apply decentralized approaches; all decisions are based on local information, and each node in the system has identical capabilities. Therefore, it is scalable for a large numbers of groups with a wide range of group sizes.
· Efficient Routing Algorithm. By exploiting the Pastry locality property to build node’s routing table, in each routing step each message will be routed to the destination via the nearest node from which the message is originated among all currently live Pastry nodes.
2.3 Network vs. Application Layer Multicast Performance
Because the protocols have to send identical packets over the same links, Application Layer multicast is inherently less efficient than the native multicast although it should be better than the unicast. Besides, since communication between two members may involve other members, generally it has larger delays. Figure 2.2 illustrates both problems by comparing the unicast, IP multicast, and application layer multicast schemes under an example of physical topology. Squares represent routers and circles are end hosts. The dotted lines represent peers in the overlay. Further, we assume that A wants to send data to other nodes in the system. Figure 2.3 a, b and c shows the unicast, IP Multicast and application layer multicast schemes respectively. In the unicast transmission, A has to replicate the message as many times as the number of recipients and send it individually. In the IP Multicast transmission, routers take the responsibility to duplicate the message. Only one copy traverses on each link and the message comes to every destination with same delays as the unicast scheme. In the application-layer multicast transmission, the message is delivered through a logical distribution tree on the application level, which makes redundant traffic on some links. In this example, because D receives the message from A via C, the delay is larger than in the direct unicast path.

Figure 2.3 The comparison of three mechanisms (a) the naïve unicast (b) IP Multicast and (c)Application Layer Multicast
3
CAN-based Multicast (M-CAN)
CAN-based multicast (M-CAN) is a flooding-based multicast that uses a CAN overlay network to perform multicast services. A scalable CAN peer-to-peer overlay network can be extended to satisfy a large number of multicast groups with distributed target applications. This chapter reviews the proposed CAN multicast algorithm together with its overlay network. By the end of this chapter we also present our improvements to increase its performance.
3.1 Content Addressable Network
A Content Addressable Network (CAN) is a network whose involved nodes virtually form a d-dimensional Cartesian coordinate space on (d+1)-torus. Every node in a CAN has an individual distinct zone, determined by coordinates, which is completely logical on the application level. This coordinate structure has no physical relation with underlying network that connects those CAN nodes. In this thesis, we will only examine the two-dimensional CAN. Figure 3.1 depicts a two-dimensional [0,1] x [0,1] coordinate space containing 5 CAN nodes. Based on those coordinates, a CAN node learns and maintains IP addresses of their neighbors, i.e. nodes whose zones are adjoining its own zone. This information is then used to create a coordinate routing table, which facilitates communication between any two arbitrary nodes in the space.

Figure 3.1 Example of 2-dimensional CAN containing 5 nodes
3.1.1 CAN Construction
The total CAN space is dynamically divided among nodes currently in the system by using a splitting mechanism. A new coming node first has to discover a node already in the CAN by using a bootstrap mechanism. It is assumed that a CAN has an associated DNS domain name which is related to the IP addresses of one or many bootstrap nodes. A new node looks up the CAN domain name in DNS to get a bootstrap node’s IP address. The bootstrap node then provides the IP addresses of several randomly chosen nodes currently in the system. After discovering the node, the new node then chooses randomly a point in CAN space to find a node whose zone will be split. Then, a JOIN message destined for that point is sent via that discovered node. While receiving the join request, the current occupant i.e. node whose zone contains the chosen point, splits its zone in half and gives the new node half of its zone. The splitting mechanism is made according to a certain order. In two-dimensional CAN, the zone is split first along x-dimension then y dimension. After that, the split node updates its routing table and announces this change to its neighbors so that the next routing will include the new node. Figure 3.2 illustrates the division of CAN space among three nodes. The first coming node A owns the whole CAN space. When B comes, A splits its zone along x-axis and gives B half of its space. When C comes and chooses a point somewhere in B’s zone, B splits its zone along y-axis and gives half of it to C.

Figure 3.2 The CAN overlay Construction
3.1.2 Routing in a CAN
In a CAN, every message contains the destination coordinates. The message is delivered from the source to the destination by following straight lines of Cartesian coordinates. As mentioned before, each node holds IP addresses and virtual coordinate zones of their neighbors to enable routing mechanisms. A node that receives a packet, reads the destination coordinates and simply forwards the packet to a neighbor that is closest to the destination (see Figure 3.3).
3.1.3 Neighboring in CAN
Two nodes are considered as neighbors if their coordinate spans overlap along one dimension. In figure 3.3, E is a neighbor of A because its coordinate zone overlaps with A’s along the y-axis, while F is not a neighbor of A because their coordinate spans do not overlap each other. Since on the basic design the coordinates lies on a torus, node B and D are also neighbors of A.

Figure 3.3 Sample of CAN routing path
3.1.4 Topology Awareness CAN overlay network
The overlay construction described in Section 3.1.1 allocates nodes to zones at random so that neighbors on a CAN are not necessarily near each other on the Internet network. Consequently, inefficient routing procedures happen very often, i.e. a packet from a CAN node in Delft has to travel across Europe before reaching its destination in a node somewhere in Twente. The Landmark-based placement is a way to improve the design of CAN overlay network to be more congruent with the underlying topology. Each joining node probes a set of landmark machines, estimates each of their network distances by measuring its round-trip-time and orders the RTTs according to increasing order. In this mechanism, the CAN space is divided into evenly sized bins and rather than choosing a random CAN node to join, the split node is randomly chosen within the bin area. These bins are clusters of nodes with same landmark ordering. Consequently, the nodes topologically close are likely to have the same ordering and will be located in the same part of CAN space.
3.2 CAN-based Multicast (M-CAN)
3.2.1 The Group Formation
There are two cases in using CAN to perform the multicast function. First, all nodes in CAN are members of a multicast group where multicasting is achieved by simply flooding the packet over the entire CAN space. Second, only some nodes participate in a particular multicast group. In this case, they have to build a separate overlay network for the group and use the routing information of the group’s overlay to broadcast messages. Let us assume that there is a multicast group called M, whose address is mapped into a point in CAN. The node B whose zone contains that point then acts as the bootstrap node for constructing a separate CAN overlay structure for M. All nodes wishing to join M then follow the same procedure explained in Section 3.1.1, by using B as the bootstrap node.

Figure 3.4 CAN overlay creation for a multicast group
3.2.2 The Forwarding Algorithm
The main reason of using a M-CAN is simplicity; the multicasting is achieved by flooding the message over the entire space. A node that receives a message floods that message to all its neighbors except the one from which it received the message. The nodes also cache the sequence numbers of received messages to avoid flooding same messages more than once. Using this flooding algorithm, a message reaches every destination without requiring any routing mechanisms to discover the network topology. However, this naive algorithm causes a large number of duplicate packets. In the worst case, a node may receive a single message from all its neighbors (see Figure 3.5).

Figure 3.5 The naive flooding algorithm
3.2.2.1 The Static Multicast Forwarding
To reduce the number of duplicate message, the author, Silvia Ratnasamy, proposed a more efficient forwarding algorithm. This algorithm is called static multicast forwarding because the node’s forwarding decision is based on the relative position of its zone to the source’s zone. We will describe the forwarding algorithm that is modified for the two-dimensional CAN; the original can be found at [7,10].
· Origin forwarding rule.
The source (A) that generates a new message forwards that message to all its neighbors (Figure 3.6a).
· General static forwarding rule.
If a node’s region overlaps with the source along the x-axis, then, on receiving a message it will forward the message to neighbors whose zone overlaps with its zone along x-axis in one direction going away from the source, and to neighbors whose zone overlaps with its zone along y-axis in two directions (positive and negative y-axis). Otherwise, it will forward it only to neighbors whose zone overlaps with its zone along y-axis going away from the source. In Figure 3.6b, all nodes in the shaded area forward the message both along x and y-axis, while others (i.e. D and E) forward the message only along x-axis.
· The halfway rule.
A node does not forward a message along particular direction if the message has already propagated halfway across the space from the source coordinates along that dimension. This rule prevents the flooding from looping round the back of the space (Figure 3.6c).
· Cache suppress rule.
A node caches the sequence numbers of received messages and does not forward the same message more than once.
· The corner filter rule. A node only forwards the message to its neighbor if its zone is in contact with the corner of that neighbor. The corner of a node is determined as follows. Let us assume that a node X touches Y along one dimension. Then the corner of Y is the one that has the lowest coordinates in another dimension. In Figure 3.6d, CM is the corner of node M, while CF is the corner of node F. Thus, node M and F receive the message only from node J and D respectively, since J and D’s zones are in contact with M and F’s corners.

Figure 3.6 The static multicast forwarding
As we can see in Figure 3.6, this algorithm still generates a number of duplicate messages. Generally, all nodes that overlap with source along y-axis (all nodes in the shaded area) and their corners contact each other on x-axis, e.g. node G, H always send duplicate messages each other.
3.2.2.2 The Dynamic Multicast Forwarding
To minimize flooding of unnecessary messages among the nodes, we introduce our improvement called the dynamic multicast forwarding. Instead of using node’s relative position, a node uses the direction from which it received message to decide its next forwarding step. However, for y-axis forwarding, we only allow to forward the message to one node per direction. This algorithm, illustrated in Figure 3.7 consists of following steps:
· Origin forwarding rule.
The source that generates a new message forwards the message to all its neighbors along the x-axis, but only one neighbor per direction on the y-axis. In Figure 3.8a, for example A only forwards the message to H and E in positive and negative direction of y-axis and to C and N along x-axis.
· General dynamic forwarding rule.
A node which receives the message along x-axis, forwards it to its neighbors whose coordinate zones overlaps with its zone along x-axis on the opposite direction from which it receives the message, and to its neighbors whose coordinate zones overlaps with its zone along y-axis. However, for forwarding along y-axis, if a node has already forwarded the message to one neighbor on a particular direction, it will not forward it to another neighbor on that direction. The chosen neighbor i.e. neighbor to whom a node will forward the messages can be determined by application codes (Figure 3.7b).
· The halfway rule.
This rule is the same as in the previous algorithm.
· Cache suppress rule.
A node caches the sequence numbers of received messages and does not forward the same message more than once.
· The corner filter rule.
This rule is exactly the same as in the previous algorithm, except it is applied only on x-axis forwarding. Similar to previous algorithm, in Figure 3.8d, M will only receive the message from J since M’s corner is in contact with J’s zone. However, in the y-axis forwarding, even though E’s zone does not touch F’s corner, E still forward the message to F.
Since the y-axis forwarding includes only one neighbor on each direction, exactly one copy of the message traverses along the positive and the negative y-axis. Therefore, duplicate message forwarding within the overlay can be avoided. The routing path on x-axis will be the same as the previous algorithms, while on y-axis it is slightly different. However, here, the message will experience more delay. In the previous example, according to the static original-algorithm, node J and G receive the message directly from the source, while in this algorithm they will receive it from H.
Although this improved protocol reduces the duplicate message forwarding, it is obviously less robust than the naive flooding algorithm, where a node may receive the message from all its neighbors. Here, if a member fails to forward the message, then the message will not reach remaining members in the CAN. However, the same thing happens in the previous algorithm (the static multicast forwarding), i.e. in forwarding along x-axis or in forwarding along y-axis in case that there is only one neighbor per direction to forward the message.

Figure 3.7 The dynamic multicast forwarding
4
SCRIBE
In this Chapter, we briefly describe the Scribe multicast algorithm together with its Pastry overlay network. Only those mechanisms relevant to our work will be explained. For more details we refer to [3,11].
4.1 PASTRY
As the demand for peer to peer systems is rapidly increasing, one of the biggest issues in this area is providing an efficient routing algorithms and object location for the large-scale applications. Pastry [11] is one of many peer to peer systems that is distributed, scalable and suitable to support a variety of applications such as global file sharing, file storage, group communication and naming systems. Compared to other peer-to-peer systems, Pastry has a major advantage of possesing the locality property to facilitate the routing mechanism among nodes. This property ensures that on each routing step the message will be routed to the destination via the nearest node from which the message is originated among all currently alive Pastry nodes.
4.1.1 Pastry Design
Each Pastry node has a unique identifier (nodeId) that ranges from 0 to 2128-1, and which is assigned randomly when a node joins the system. The identifiers are generated such that they are uniformly distributed in the128-bit circular space. For the purpose of routing, those nodeIds are presented as a sequence of digits in base 2b (b is a parameter with typical value 2 or 4).
4.1.2 Routing in Pastry
To route a message, a node uses a leaf set and a routing table that consist of entries where each entry maps a nodeId to the associated node’s IP address. A leaf set, L, consist of 2b or 2x2b entries, which are filled with nodes that have numerically closest nodeIds to the owner’s Id, |L|/2 being smaller and |L|/2 being larger. A routing table, R, consist of 128/b rows with 2b entries on each row. The n-th row of a node’s routing table entries are filled with nodes whose nodeIds match with the present node on the first n digits, while column c of the n-th row indicates the value of (n+1)-th digit of those nodes. If there is no node that fulfill the criteria for an entry, then that entry is left empty.
Figure 4.1 depicts an example of a leaf set and routing table, owned by a node with nodeId 12030321 and b equal to 2. All numbers shown in Figure 4.1 are in base 4. The shaded entry on each row shows the digit value of the owner’s nodeId on that row. Now let us take a look at the second row of the routing table, which is row one. Entries in that row are filled with nodes whose nodeIds match with the owner on the first one digit, or in other words, the first values of their nodeIds are 1. Then, in row one, column zero is intended for a node whose first two digit values are 10, column one is for the one whose first two digit values are 11, etc.

Figure 4.1 The Leaf Set and Routing Table
It is possible that there are several nodes that fulfill the criteria for an entry. With the Pastry locality property, the present node is capable of choosing the nearest node among all potential candidates. The locality property is a function that enables a node to determine its “distance” to another node given the IP address of that node. Figure 4.2 shows the routing table creation using the locality property. The owner has nodeId 1203031. To fill the first column of the first row in its routing table, it has to find a node whose prefix matches on the first one digit and the second digit value is 0. If we assume that there are four nodes that fulfill the criteria (the first two digit values are 10), then it should choose one of them. By applying the locality, the nearest node is chosen to fill in the entry.
With the uniform distribution of nodeIds, on average, for each routing table only 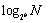
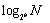 rows are filled, where N is the number of nodes that exist in the Pastry overlay network. Therefore, generally, each node only maintains [
rows are filled, where N is the number of nodes that exist in the Pastry overlay network. Therefore, generally, each node only maintains [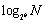 ] * [2b-1] + L entries for message routing.
] * [2b-1] + L entries for message routing.

Figure 4.2. The Locality property in creating routing table

Figure 4.3 Routing in Pastry circular space
The Pastry’s routing procedure is explained as follows. On receiving a message, a node first looks at its leaf set whether the destination key falls in the range of the leaf set. If the leaf set does not contain that key, the node starts looking at its routing table to find node whose nodeId is closest to the key. In each routing step, the message will be forwarded to a node whose nodeId matches the prefix with the key at least one digit longer that the present node. If such node is not available in the routing table, the current node will look back to its leaf set and find a node whose nodeId not only matches the prefix as long as itself, but is numerically closer to the key.
4.1.3 Routing Performance
Assuming there are no node failures, the average number of the routing steps in Pastry is log2bN. This value is gained because when routing tables are used to perform routing, the matched prefix of the source and the destination key is reduced at least by factor 2b on each step. The best case occurs when the key is in the range of source’s leaf set and the message is routed directly to the key, while the worse case occurs when the key is not in the range of leaf set and the appropriate table entry is empty. In the last case, with high probability, the message will experience no more than one additional routing step that gives expected result.
4.1.4 Locality Property
As mentioned above, Pastry has a major advantage over other peer-to-peer systems by having locality property i.e. the property of Pastry’s routes with respect to the proximity metric. This proximity metric reflects the “distance” between two arbitrary nodes in the network, such as the round trip time. It is assumed that there is a function that enables each Pastry node to determine its relative “distance” to another node given the node’s IP address. This property ensures that at each routing step a message will be delivered not only to the node with numerically closer nodeId but which is also topologically nearer to the key, because the routing table is filled by a topologically nearest node among all candidates (see Figure 4.2).
4.2 SCRIBE
Scribe is a tree-based application level multicast infrastructure built on top of Pastry. It uses Pastry to build a per-group multicast tree. Both Pastry and Scribe apply decentralized approaches; all decisions are based on local information, and each node in the system has identical capabilities. Therefore, it is scalable for a large numbers of groups with a wide range of group sizes. Besides, the randomized addressing of nodes guarantees the tree balance. Furthermore, as a consequence of a symmetric communication of peer-to-peer applications, each node can act as a multicast source, a root of a multicast tree, a group member, a node within a multicast tree, or any possible combination of the above. All Pastry nodes that run the Scribe application software can be Scribe nodes.
4.2.1 Group Management
Each group has a unique groupId and a rendezvous point as the root of the group multicast tree. Choosing the rendezvous point can be done in several ways. The Scribe node with a numerically nodeId closest to the groupId acts as the rendezvous point for the associated group. To create a group, a Scribe node asks Pastry to route a create message using the groupId as the destination key. Pastry delivers this message to the node whose nodeId is numerically closest to the groupId. This Scribe node then becomes the rendezvous point for that group. Alternatively, the root can also be the node that creates the group. A good choice of group creator e.g. node that sends most often, or the closest to other frequent senders in the network, can increase the performance.
4.2.2 Membership Management
Scribe creates a multicast tree using a scheme similar to reverse path forwarding to distribute the message among group members. A per group tree is created by combining Pastry paths from each group member to the rendezvous point. The Pastry properties ensure that there will not be any loops in the tree, since the nodeId of the next node in every hop of Pastry route matches a longer prefix of the groupId longer than the previous node, or matches a prefix of the same length but is numerically closer to the groupId.
In Scribe, joining group operations are managed in a decentralized manner to support large and dynamic membership. Joining requests are maintained locally in a decentralized fashion so that in particular the rendezvous point does not handle all joining requests. Because of randomized addressing, the load to forward multicast messages within the multicast tree is also well distributed among the group members. Hence, this mechanism is efficient for groups with a wide range of mem, berships.
4.2.3 Joining the Multicast Group
To join a group, a node sends a join message by using the groupId as the destination key. Pastry then routes this message until it reaches the group’s rendezvous point. The group’s multicast tree consists of Pastry nodes, called forwarders, which may or may not be the members of that group. Each of them maintains a children table of the group containing an entry (IP address and nodeId) for each of its children in the tree. Each node along the route checks whether it is already a tree member. If it is not, it creates a children table for the group, adds the preceding node to its children table and forwards the join message to the next node. Otherwise, it adds the preceding node to its child and terminates the join message. Figure 4.4 demonstrates this joining procedure. In this example b=2 and the groupId (or root’s nodeId) is 3021. The node with nodeId 0311 wants to join this group. In this example, the join message follows the path 3231, 3012 and 3021. If we assume that nodes 3231 and 3012 are not members for multicast tree for that group, then they have to create children tables and add the preceding node in the route to their children tables. If we assume that node 1213 decides to join the same group, since node 3231 is already a forwarder, it only adds node 1213 to its children table for the group and stops forwarding the message to the next node.
4.2.4 Multicast Message Distribution
Multicast messages are distributed from the rendezvous point along the multicast tree. A node wishing to send a message to the group should deliver it first to the rendezvous point. The source asks Pastry to route the message and requests the rendezvous point to return its IP address. A single multicast tree is built for each group and all multicast sources use the same procedure to multicast message to the group.

Figure 4.4 Join mechanism
5
Simulation Design
In this Chapter, the simulation design is discussed. We simulated six multicast schemes, namely IP multicast, the static forwarding CAN-based multicast (denoted as M-CAN1), the dynamic forwarding CAN-based multicast (denoted as M-CAN2), Scribe without the topology awareness (denoted as Scribe1), Scribe with the topology awareness (Scribe2) and m-times unicast on the same underlying topologies and the same general scenarios. In M-CAN and Scribe simulation, some modifications of those scenarios were carried out to get better investigation. Finally, in each simulation we computed the hop count as the criterion to evaluate their performance.
5.1 General Scenario
· Generate a random topology with N nodes (routers). We used random graph with link weights equal to 1 and link density p=0.2.
· Choose randomly M out of N routers to which M multicast member are attached. As will be explained later in section 5.2.4, for Scribe simulation, a number of Pastry (NPastry) nodes are attached randomly to N routers. To get closer to the reality, we considered two scenarios. In the first scenario (denoted as scenario-a), some multicast members (or Pastry nodes) are attached to the same routers (Figure 5.1-1), while in the second scenario (denoted as scenario-b), each member is attached to a different router(Figure 5.1-2).
· Choose the multicast source and perform m times unicast and four different multicast schemes.
· Iterate the number of sample topologies. Due to time limitations, for 500 nodes we only iterated i=1,000 topologies while for 100 and 200 nodes we iterated up to i=10,000 different topologies. For each sample topology, the configuration (the number of multicast members or Pastry nodes and the attached routers) was not changed.
· Change the combinations of M and N, with same ratios (r) M/N. For N=100 and N=200, r was chosen to be 0.05, 0.1, 0.2, 0.5, 0.7 and 0.9, while for N=500 due to time limitations, topology awareness and multiple overlay M-CAN simulations only covered r=0.01, 0.02, 0.05, 0.1. For Scribe simulations, we also varied the value of NPastry.

Figure 5.1-1 Five multicast members attached to random routers in the underlying topology where some members are attached to a same router (scenario-a)

Figure 5.1-2 Five multicast member attached to random routers in the underlying topology where each member is attached to a different router (scenario-b)



